Come funziona Google: guida al funzionamento di un motore di ricerca
Non è possibile fare SEO senza conoscere il funzionamento di un motore di ricerca, ovvero senza conoscere come funziona Google. Esattamente per lo stesso motivo per cui non è possibile fare il meccanico ignorando il funzionamento del motore di un’automobile.
In questo capitolo cercheremo di spiegare nel miglior modo possibile come funziona un motore di ricerca, evitando di annoiare con tecnicismi da ingegneria del software. In fondo all’articolo però suggeriremo delle risorse per chi vuole approfondire l’argomento dal punto di vista informatico.
Fasi di funzionamento di un motore di ricerca
Google, così come gli altri motori di ricerca, è un’insieme di software molto sofisticati che mirano ad individuare il corretto intento di ricerca dell’utente, analizzare un immenso database alla ricerca delle risposte più pertinenti e qualitative per infine fornire un set di risultati ordinati: la SERP.
È possibile racchiudere tutto questo processo di elaborazione in due fasi di lavoro ben precise:
- Prima della ricerca;
- Durante e dopo la ricerca;
Analizziamo dunque queste fasi per avere un’idea più chiara su come funziona la ricerca su Google.
Funzionamento di Google, fase 1
Per sapere come funziona Google occorre anzitutto analizzare cosa avviene prima della ricerca. L’obiettivo della prima fase è la creazione dell’indice. Per farlo verranno sostanzialmente eseguiti tre processi di elaborazione:
- Crawling;
- Parsing;
- Indexing (indicizzazione).
Crawling
Nessuna ricerca può essere elaborata in assenza di un indice. Quindi prima che ogni ricerca avvenga, Google sonderà l’intero web per acquisire informazioni. Per farlo si avvarrà di software molto semplici, chiamati crawler o spider.
Gli spider altro non sono che dei bot (script) progettati per acquisire il contenuto di una pagina web, da inviare successivamente a dei software più complessi in grado di comprenderne il contenuto (parsing) e creare un indice da memorizzare in una grande banca dati.
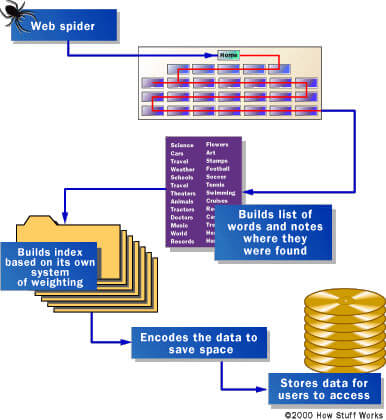
A seconda dell’importanza che il motore di ricerca attribuisce ad ogni singolo sito web, allo spider viene dato un tempo massimo per analizzarne i contenuti, chiamato crawl budget.
Uno spider scopre nuove pagine e nuovi siti web grazie ai link, il vero punto di collegamento esistente nel web. Tuttavia, per velocizzare questo processo, oggi è possibile avvisare Google della presenza di nuove pagine e nuovi siti mediante strumenti come la Sitemap o direttamente dalla Search Console.
Parsing
La fase di parsing, quella dell’analisi del contenuto, è molto importante in quanto anche le query di ricerca successivamente saranno trasformate allo stesso modo per poter fare i confronti. Durante questa fase vengono applicate diverse modifiche al testo per renderlo di più facile comprensione agli algoritmi, come:
- lo stopping, ovvero la rimozione delle stop words (preposizioni, congiunzioni, ecc..);
- lo stemming, ovvero il raggruppamento di parole avente una radice comune (calcio, calciatore, calciatori, portiere, attaccanti, ecc..) per aumentare la probabilità di corrispondenza tra query e pagina web.
Naturalmente non finisce qui. Altre semplificazioni ed estrazioni vengono fatte per determinare altre informazioni che Google può usare per rispondere in modo efficace alle query di ricerca.
Un tempo Google dava maggiore importanza ai termini indicati in punti strategici della pagina web, come il titolo, le intestazioni h1, h2, h3, la URL, le meta description, il tag alt delle immagini, ecc.. Sebbene rimanga un buon punto di partenza inserire la parola chiave principale nei punti strategici, la ricerca dimostra che la sua influenza è decisamente diminuita.
Indicizzazione
Una volta completata la trasformazione del testo avviene l’ultima fase, l’indicizzazione, che non è da confondersi con il posizionamento. Molto brevemente Google crea un elenco di pagine web a cui viene associato un termine. Esempio:
- calcio: pagina1, pagina256, pagina865, ecc..
- ciclismo: pagina3, pagina76, pagina132, ecc..
e così via. Questo elenco è chiamato indice ed ha come obiettivo quello di velocizzare il processo di ricerca. Chi si intende di programmazione e database padroneggia già questo linguaggio e ben comprende quanto un indice velocizzi il risultato di una query, special modo in database molto grandi.
Quindi l’indicizzazione è di per se un ordinamento primordiale comandato da un modello algoritmico detto TF-IDF, il cui obiettivo è dare più importanza ai termini che compaiono più spesso nel documento ma che in generale sono poco frequenti:
- TF (Term Frequency): indica la frequenza del termine all’interno della pagina web, ovvero quante volte è presente;
- IDF (Inverse Documents Frequency) indica la frequenza del termine all’interno di tutte le pagine web dell’indice, attribuendo più importanza ai termini presenti in poche pagine web (ecco perché inversa).
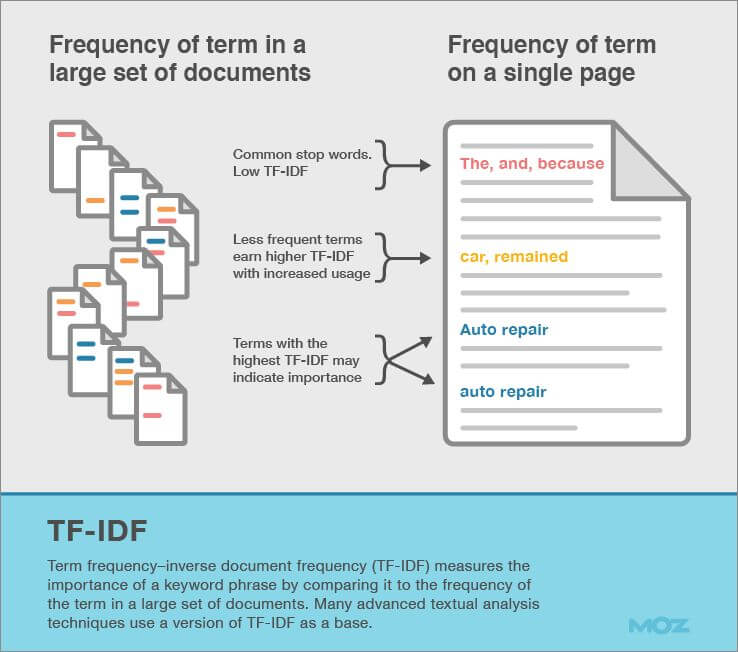
Di seguito la formula matematica per il calcolo del valore di TF-IDF:
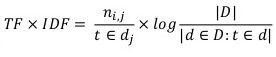
Con l’avvento dell’update Hummingbird questo modello si è evoluto e adesso è in grado di intercettare con maggiore precisione i reali intenti di ricerca degli utenti grazie ad una maggiore comprensione dei testi, dei sinonimi e dei termini correlati.
Funzionamento di Google, fase 2
Durante la ricerca Google inizia a reperire le informazioni che si stanno ricercando. Anche in questa fase vengono sostanzialmente eseguiti tre processi di elaborazione:
- Interazione;
- Ranking;
- Valutazione dei risultati.
Interazione
Durante il processo di interazione avviene un parsing molto simile a quello visto nella fase 1. La query di ricerca viene trasformata e scomposta nei suoi termini per poi effettuare un’analisi delle cooccorrenze dei termini nelle pagine web dell’indice e nelle query precedenti.
L’algoritmo cercherà di decifrare il linguaggio e di comprenderne anche i sinonimi, i quali influenzano una buona percentuale delle query di ricerca. Grazie alla sua capacità di imparare dalle query precedenti e dall’intersecazione dei sinonimi, durante la ricerca Google potrebbe suggerire nuove query con termini correlati, il famoso Google Instant.
A dimostrazione della capacità di comprensione dei sinonimi, proviamo ad effettuare una ricerca per la vendita di trolley online. Vedremo subito come tra le prime posizioni sono presenti risultati nel cui tag title la parola trolley non figura.
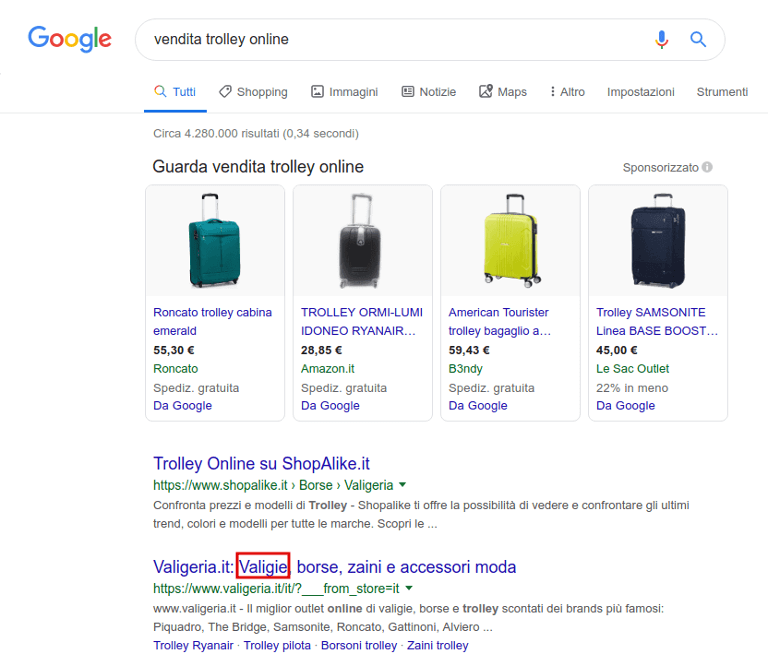
Uno dei migliori risultati, infatti, presenta il sinonimo valigie. Gli algoritmi sono sempre più in grado di riconoscere sinonimi, termini simili, variazioni grammaticali ed errori grammaticali, quindi la scrittura naturale e non forzata è quella che restituisce i migliori risultati.
Ranking
L’obiettivo di capire come funziona Google è quasi sempre legato al miglioramento del ranking delle pagine di un sito web per avere vantaggi diretti sui propri competitor. Il ranking è la fase più complessa di tutto il processo e consiste nel classificare i risultati di ricerca in base alla corrispondenza tra query e pagine web.
Per farlo, dei complessi algoritmi intrecciati tra loro calcolano il valore di rilevanza ed importanza della pagina web, prendendo in considerazione anche il trust e l’autorevolezza del sito web.
Per rilevanza si intende il grado di corrispondenza tra l’intento della query ed i risultati mostrati. Più una pagina web contiene termini pertinenti alla query (compresi i sinonimi) e link da pagine altrettanto pertinenti, più la sua rilevanza aumenta.
L’importanza invece è misurata in base alle citazioni che la pagina riceve. Sostanzialmente più gli altri parlano bene di noi e più accresce l’importanza nei nostri confronti. Nel web le citazioni sono i backlinks. Più fonti importanti citano la pagina e più la sua importanza aumenta.
La combinazione tra rilevanza e importanza si traduce in un punteggio che determina il posizionamento in SERP di una pagina web. Mentre un tempo erano pochi i fattori di ranking che determinavano tale punteggio, e soprattutto facilmente influenzabili, oggi sono oltre 200, tra cui:
- Freschezza dei contenuti;
- Qualità dei contenuti;
- Link in ingresso e qualità degli stessi;
- Parole e sinonimi all’interno del contenuto;
- Controllo ortografico;
- Tipologia di contenuto (video, testo, immagine, ecc..);
- URL;
- Titolo della pagina;
- Mobile friendly;
- Tempo di caricamento;
- Menzioni sui social network;
e così via. In una non proprio recente intervista a Search Engine Journal, Andrey Lipattsev dichiara che i segnali più importanti per Google sono sostanzialmente tre: contenuto, link e RankBrain.
Mentre i primi due sono molto famosi e riconosciuti, l’ultimo potrebbe non esserlo altrettanto. Molto brevemente RankBrain è il nome che Google ha dato al suo sistema di intelligenza artificiale di machine learning che viene utilizzato per aiutare a elaborare i miliardi di risultati di ricerca.
Il machine learning, o apprendimento automatico, è il modo in cui un computer impara da se stesso senza l’intervento di un essere umano e senza seguire rigide regole di programmazione.
RankBrain è parte fondamentale dell’algoritmo di ricerca di Google che aiuta a riconoscere quali pagine sono più pertinenti per determinate query.
Valutazione dei risultati
Google mette sempre al centro l’esperienza utente. Dal momento in cui un utente cerca e clicca su un risultato di ricerca, inizia un monitoraggio per capire se il sito web piace o meno.
Se ad esempio un utente dopo il clic su un risultato di ricerca torna indietro e clicca altri risultati, se esce immediatamente dal sito prima ancora che questo venga caricato o se presenta un tempo di permanenza troppo basso, comunica a Google un’esperienza utente negativa, ovvero bassa qualità.
Se a seguire questo comportamento sono in molti, allora probabilmente il sito web soffre di problemi di usabilità o il contenuto non risponde esattamente alla query di ricerca e Google prenderà i suoi provvedimenti affinando sempre più i risultati.
Altro modo per monitorare l’esperienza utente è l’utilizzo di Quality Rater, ovvero esseri umani il cui compito è valutare i risultati di precise SERP e dare dei voti da 1 a 5 sulla qualità delle pagine web in relazione ad una data query.
Libri e approfondimenti sul funzionamento di un motore di ricerca
Un libro che consigliamo a chi tecnicamente vuole saperne di più sul recupero delle informazioni è Modern Information Retrieval: The Concepts and Technology Behind Search.

È un libro pensato per gli studenti che fornisce una visione aggiornata sul recupero delle informazioni, incluso il recupero dal web, la scansione web, i motori di ricerca open source e le interfacce utente.
Dall’analisi all’indicizzazione, dal raggruppamento alla classificazione, dal recupero alla classifica e dal feedback degli utenti fino alla valutazione dei dati recuperati, semplificando con esempi tutti i concetti più importanti.
Su Amazon è disponibile una nuova edizione completamente riorganizzata, rivista e ampliata con un numero doppio di pagine rispetto l’edizione precedente e con in più un sito web ricco di materiale didattico.
Un altro approfondimento è l’intervento How Google Works: A Google Ranking Engineer’s Story di Paul Haahr al SMX West 2016. Insieme ad un professionista del calibro di Gary Illyes, Paul Haahr offre una visione interna di come Google determina il posizionamento.
In conclusione conoscere il funzionamento di Google è importantissimo per poter effettuare qualunque tipo di ottimizzazione sul sito web. In questo articolo abbiamo voluto dare una panoramica molto esemplificativa sul funzionamento di Google dalla quale si evincono la sua complessità ed intelligenza ma soprattutto il suo mettere sempre al centro l’esperienza utente.
Il primo passo per migliorare il posizionamento sui motori di ricerca è proprio questo, fornire informazioni di alta qualità pertinenti alle query di ricerca, e pensare che a leggere siano gli utenti.
Se ti è piaciuto questo articolo e vuoi essere aggiornato sulla pubblicazione di quelli nuovi, iscriviti gratuitamente alla nostra newsletter. Non riceverai mai spam, lo odiamo tanto quanto te.





